Serverumzug
Den Beginn des Pfingstwochenendes haben sich Chandi und ich ausgesucht, um uns allen die Freude an der Benutzung der foodsharing-Plattform zurückzuholen: Wir ziehen auf einen schnelleren Server um. Die Geschichte dazu möchte ich euch an dieser Stelle erzählen. Dieser Beitrag entsteht während des Umzugs - einerseits in Prokrastinationspausen, andererseits in Zwangspausen, während ich auf irgendetwas warten muss :-)
Was viele vielleicht nicht wissen, ist, dass der Kern der foodsharing-Entwickler die Plattform nur sehr sporadisch nutzt. So kam es vor zwei Wochen, dass ich mal wieder auf foodsharing.de gegangen bin, um nachzuschauen, ob ein Bug dort bereits vorhanden war und ich mich dabei ziemlich genervt davon gefühlt habe, dass die Plattform extrem langsam ist. Wir wussten eigentlich schon, dass wir so langsam ziemlich am Limit unseres Servers sind, aber es selbst zu spüren, ist nochmal was anderes.
Kurzerhand habe ich mich daraufhin freundlich und zurückhaltend an unseren Server-Sponsor Manitu gewendet und nachgefragt, ob wir - u. U. auch mit Zuzahlung einer kleinen Summe - einen schnelleren Server bekommen können, da sich unsere Nutzerzahlen aber auch die Komplexität unserer Anwendung stetig weiterentwickeln.
Die Antwort kam nach wenigen Stunden vom Chef persönlich: Sehr gerne wird foodsharing weiter unterstützt. Ein Mitarbeiter schaut zeitnah mal, was sie uns aus dem Reste-Pool anbieten können. Meine Freude - und auch die im weiteren Team, mit dem ich die Nachricht schnell geteilt habe - war groß. Zwar wussten wir, dass wir mit Manitu als inhabergeführtem Unternehmen “Von Menschen für Menschen” einen guten Partner an der Hand haben, aber es ist wundervoll, auch nach so vielen Jahren weiterhin so eine Unterstützung und positive Kommunikation zu erfahren.
Los gehts: Planung
Nach kurzer Zeit ist geklärt, dass wir den Server in der Woche um den 5. Juni gestellt bekommen. Chandi - selbst Administrator von mehreren Servern für Projekte im ähnlichen Kontext - bietet mir seine Erfahrung und Unterstützung an, den Umzug vorzubereiten und durchzuführen. Wir tauschen uns ein wenig über Ideen und Wünsche an das neue System aus und erstellen einen Plan:
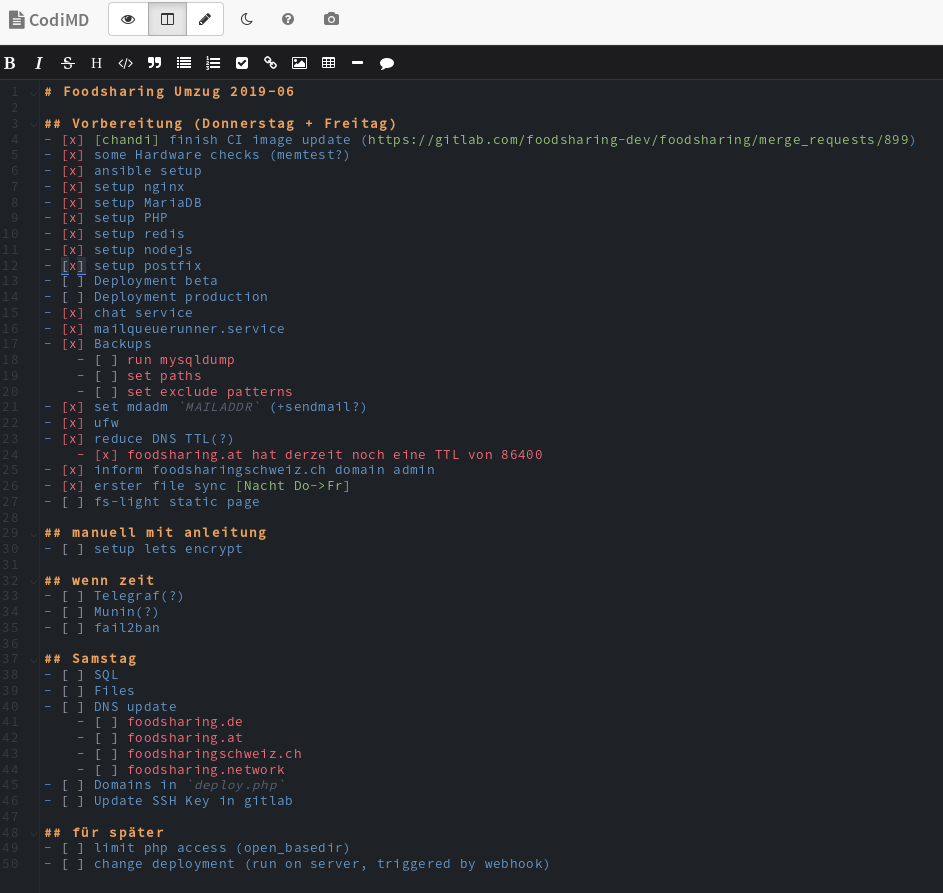 Umzugsplan im CodiMD Pad, Stand Samstag, 12:00 Uhr. Wir hinken ein kleines bisschen hinterher.
Umzugsplan im CodiMD Pad, Stand Samstag, 12:00 Uhr. Wir hinken ein kleines bisschen hinterher.
Der wichtigste gemeinsame Wunsch von uns ist, eine reproduzierbare Konfiguration des Servers zu haben. Ein typisches Problem einzeln administrierter Server ist, dass über die Zeit immer wieder Menschen etwas an der Konfiguration ändern und es von außen schlecht nachvollziehbar ist, was genau eigentlich mit welchen Einstellungen läuft. Bei uns ist das Problem noch stärker: Für viele Entwickler ist die exakte Konfiguration einer Systemkomponente immer mal wieder interessant, eventuell möchte ein*e Entwickler*in diese sogar ändern. Serverzugriff ist immer mit Zugriff auf sensible Daten verbunden: Den haben bei uns nur sehr wenige Personen.
Eine Lösung dafür ist es, die Konfiguration des Servers komplett in Skripte auszulagern, welche dann dort lediglich ausgeführt werden, jedoch immer nur an zentraler Stelle verändert werden. Die Lösung, für die wir uns entscheiden, ist das Tool Ansible. Es ermöglicht nicht nur die Ausführung von Skripten sondern erlaubt die Beschreibung des Zustands einer Installation. Änderungen können dadurch leichter eingearbeitet werden. Zudem haben wir mit diesem Tool schon einige Erfahrung gesammelt.
Das Ziel: Die Konfiguration nahezu vollständig mit Ansible umzusetzen, sodass manuelle Eingaben am Server nahezu unnötig sind.
Die Ansible-Konfiguration könnt ihr euch im dragonfruit-ansible Git-Repository anschauen und habt damit die Möglichkeit nachzuvollziehen, wie der foodsharing-Server exakt eingerichtet ist. Zudem kann jeder Mensch auch hier Verbesserungen beitragen bzw. vorschlagen. Das Ausführen der Änderungen auf unserem Server obliegt jedoch den Menschen mit entsprechendem Zugriff. Das sind im Moment Nick und ich.
Nun aber: Server einrichten
Nach einigen Stunden Planung haben wir den Donnerstag und Freitag damit verbracht, die Konfiguration des bestehenden Servers in das Ansible-Repository zu übertragen. Da wir gleichzeitig auch einige Software-Pakete updaten, gehört immer wieder dazu, die Konfiguration nachzuvollziehen und anzupassen. Bis Freitagabend haben wir zusammen etwa 30 Stunden investiert.
Bevor es nun ans eingemachte geht soll der Server noch einmal frisch installiert werden. Ein Klick im Manitu Web-Interface erlaubt die frische Installation verschiedener Linux-Distributionen. Wir entscheiden uns für Debian Stretch, die aktuelle, stabile Version des bekanntesten, häufig für Server genutzten Linux.
Und dann passiert… nichts. Der Server startet nicht automatisch neu, installiert sich nicht neu.
Leider ist es schon Freitag, 21:30 Uhr, als ich das bemerke. Der Manitu-Support wird jetzt wohl schon im Wochenende sein. Die Vermutung liegt nahe, dass das Management-Interface nicht richtig angeschlossen ist und der Server nicht auf dieser Ebene ferngewartet werden kann.
Ich denke daran, dass wir theoretisch eine eigene Möglichkeit zur Fernwartung haben: Es handelt sich um professionelle Server-Hardware, welche über IPMI verfügt. Diese Schnittstelle ist quasi ein kleiner Computer im Computer, der unabhängig über das Internet erreicht werden kann und den Server ein/ausschalten kann, eine Remote-Konsole zur Verfügung stellt und sogar Tastatur-, Maus-, und Bildschirmweiterleitung bereitstellen kann. Glücklicherweise habe ich am Tag vorher vom Support IPMI schon freischalten lassen. Aus Sicherheitsgründen ist der Zugriff durch eine Firewall geschützt. Wir können nur über einen anderen unserer Server - carrot, der Server für Cloud und Wiki - darauf zugreifen.
Mir ist die Zeit etwas im Nacken: Wir benötigen etwa 8 Stunden, um alle Profil- und Essenskorbbilder vom alten Server auf den neuen umzuziehen. Dies soll in der Nacht vor dem Umzug geschehen, damit am Samstag nurnoch ein paar neue Bilder übertragen werden und die Ausfallzeit idealerweise auf wenige Stunden reduziert werden kann. Leider ist es inzwischen 22 Uhr.
Während ich mich über IPMI einlese und schonmal einen Neustart des Servers darüber auslösen kann, schreibe ich trotzdem dem Manitu-Support und frage mal höflich, ob da eventuell das Reset-Interface hängt und gehe schon davon aus, dass vorm Dienstag - wir bedenken: Montag ist Pfingsten - nichts mehr passieren wird.
Nebenbei bemerke ich, dass der Server die Neuinstallation angefangen hat. Toll! Leider ist die Freude kurz: Nach weiteren 20 Minuten sehe ich, dass die Neuinstallation mit einem Fehler abgebrochen ist. Ich liebe Fehlermeldungen, leider wird hier keine angezeigt und lediglich auf den Support verwiesen :-(. Ich versuche, die Bildschirmweiterleitung (“KVM”) mittels IPMI zu verwenden, um dort Rückschlüsse auf den Fehler zu bekommen. Das Tool IPMIView funktioniert leider nur so mäßig, da ich es über X-Forwarding benutzen muss. Nach einigen Minuten der Benutzung einer Suchmaschine meiner Wahl finde ich heraus, dass ich die KVM-Weiterleitung auch über einen SSH-Tunnel von Port 5900 auf meinem Rechner lokal ausführen kann und ein Unterprogramm von IPMIView direkt ausführen kann. Der Befehl:
java -Djava.library.path=. -jar iKVM.jar 127.0.0.1 $USER $PASSWORD null 5900 623 2 0
verschafft mir wirklich ein Bild:
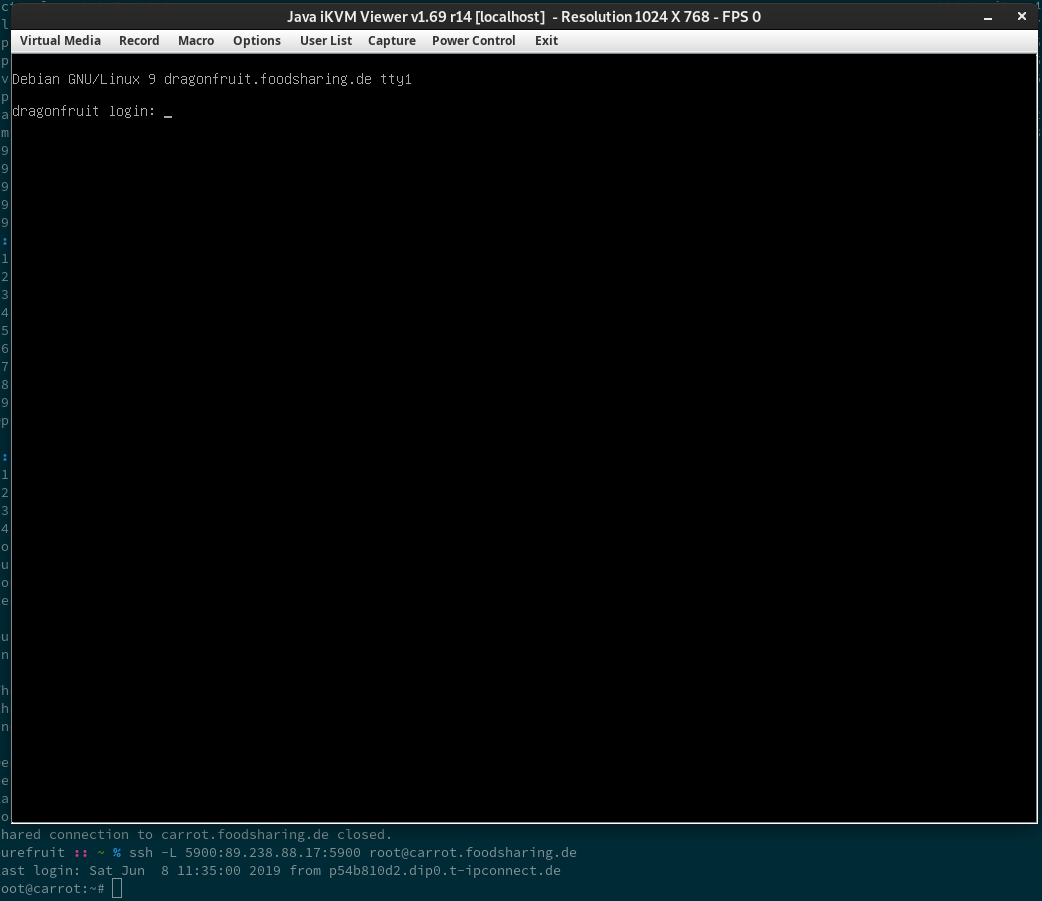 IPMIView KVM Weiterleitung über SSH Tunnel, nachgestellt am Samstagmorgen
IPMIView KVM Weiterleitung über SSH Tunnel, nachgestellt am Samstagmorgen
In der Zwischenzeit bemerke ich, dass der Manitu-Support mir geantwortet hat. Um 23:36 Uhr an einem Freitagabend habe ich eine Antwort auf eine normale, kostenfreie Supportanfrage bekommen! Ich bin begeistert. Der Mitarbeiter liefert mir zwei entscheidende Hinweise:
- Leider kann er zu dieser Zeit nicht am Server nachschauen. Ich müsste eine kostenpflichtige Remote-Hand buchen, um das Reset-Interface sofort zu testen. Andernfalls erfolgt es am Dienstag.
- Sein System zeigt, warum die Neuinstallation fehlgeschlagen ist: Anscheinend hat sich das Installationsskript beim Partitionieren der SSDs verschluckt. Ich bekomme den Rat, diese manuell zu löschen und es erneut zu probieren.
Ich habe überhaupt nicht mit einer so raschen Antwort gerechnet und finde es total gerechtfertigt, dass das eigentliche Problem nicht sofort gelöst werden kann. Der zweite Hinweis wirkt: Nach einem Secure Erase der SSDs läuft die Neuinstallation erfolgreich durch.
Inzwischen ist es Samstag. Um 00:30 Uhr logge ich mich in den frisch installierten Server ein, starte die Konfiguration mittels des bis dahin relativ weit fortgeschrittenen Ansible-Projekts und habe nach wenigen Sekunden einen fast fertig eingerichteten foodsharing-Server. Wunderbar :-)
Ich hatte zwischenzeitlich schonmal im Team kommuniziert, dass es gerade Probleme gibt, die uns zu einer Terminverschiebung zwingen könnten. Das darf ich nun also guten Gewissens durchstreichen:
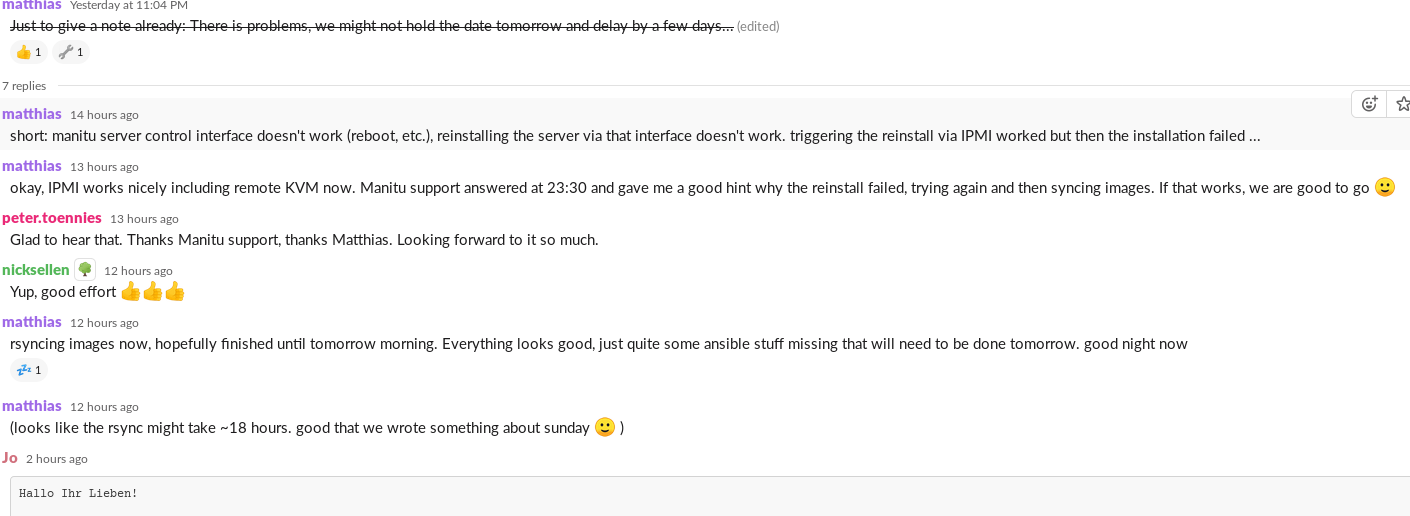 Thread im #foodsharing-dev Slack
Thread im #foodsharing-dev Slack
Ich starte den Synchronisierungsvorgang der Bilder vom alten Server zum neuen, deaktiviere die Backups auf dem alten Server weil die sonst zuviel IO-Kapazität gezogen hätten und das Kopieren ewig dauern würde und gehe gegen 1:30 Uhr einigermaßen entspannt und zufrieden schlafen.
Weiter geht’s
Samstag um 09:00 gehts mit Kaffee und nach einem netten Frühstück weiter. Glücklicherweise ist der Kopiervorgang schon fertig, auch wenn es zwischendurch so aussah, als könnte der länger dauern. Ein Blick in die Zugriffsstatistiken offenbart, dass nicht weniger los ist als an sonstigen Samstagen. Unsere Ankündigung der Auszeit wird also offenbar nicht so ernst genommen :-).
Ruck zuck ist es 13 Uhr - obwohl “eigentlich alles fertig ist”, verbringe ich den ganzen Tag mit kleineren Anpassungen:
- Chandi überarbeitet das Letsencrypt Setup nochmal etwas
- Ich richte das E-Mail-System ein und stolpere dabei darüber, dass ich das Paket
libsasl2-modulesinstallieren muss, damit unser Mailserver sich an einem anderen anmelden kann, ohne eine nicht ganz hilfreiche Fehlermeldung zu liefern - Gegen 15 Uhr bemerke ich, dass die E-Mail-Anhänge für eingehende E-Mails in das interne E-Mail-System nicht mit synchronisiert - und nebenbei auch nie gebackupt - worden. Naja, ab jetzt schon :-)
- Kurze Zeit später stoße ich alle DNS Änderungen an und nehme die Seite das erste mal auf dem neuen Server in Betrieb. Es läuft gut. Ich entscheide mich aber, den Wartungsmodus noch einige Zeit aktiv zu lassen, um alle Komponenten ausführlich zu testen. Für Menschen, die nginx-Konfigurationen lesen können, finden sich im Ansible-Repository alle Hinweise, wie foodsharing.de trotz Wartungsmodus benutzt werden kann. Bitte nicht ohne Absprache nachmachen (sondern lieber dem Entwickler-Team beitreten!)
- Den Rest des Abends schlage ich mich noch mit der Einrichtung von PHPMyAdmin zur Datenbankadministration (bäh, keine aktuelle APT-Paketquelle), munin und telegraf zum Monitoring herum.
Die eigentliche Inbetriebnahme - rm /var/www/{production,beta}/current/maintenance_mode_on - verläuft sehr unspektakulär. Es funktioniert einfach und die Seite fühlt sich auch nach wenigen Minuten, trotz einiger Seitenaufrufe pro Sekunde, noch sehr viel schneller als früher an.
Zwischenfazit
- Alles dauert wie immer länger als geplant
- Donnerstag nachmittag richtig anfangen war gerade so rechtzeitig
- Der Serverumzug hat um die 100 Personenstunden im Entwicklerteam gebunden (“Marktwert” also um die 7000 Euro), dennoch wurden nur ungefähr 2 Liter Kaffee konsumiert (und ich wäre mit 2 Tassen weniger vermutlich produktiver gewesen…)
- Ansible macht alles langwieriger, zahlt sich aber hoffentlich irgendwann aus
- Es macht Spaß zu sehen, dass alles zügiger geworden ist
Am Sonntag um 09:00 Uhr starte ich das Backup erneut, weil es in der Nacht nicht erfolgreich durchgelaufen ist (menschliches Versagen…). In der Vergangenheit hieß Backup am Anfang des Monats immer, dass foodsharing für 1-2 Tage sehr langsam war. Jetzt ist 10:55 Uhr, das Backup ist gerade fertig und foodsharing rannte nebenbei so schnell wie nie :-)
Unser Performance-Monitoring für die Startseite (vollständige Antwort auf den ersten HTTP Request “/”) verbessert sich von ~70-180 ms auf ~17-40 ms, während die CPU-Last an einem Sonntag morgen von ~30-40 % auf ~7-15 % gefallen ist. Die Antwortzeit der Festplatten (Average IO wait) fällt von durchschnittlich ~70-150 ms auf etwa 2 ms (yay, SSDs :-) ), während gleichzeitig die Auslastung von 30-70 % auf unter 10 % fällt.
Wat isn dat jetzt fürne Kiste?
- Alter Server, banana.foodsharing.de
- AMD Phenom(tm) II X4 955 Processor (4 x 3.2 GHz, ~2010)
- 8 GB Ram
- 2x 1 TB 7200rpm HDD als RAID1 (effektiv ~200 IOPS read, ~75 IOPS write)
- Debian 8, jessie (+ einige aktuelle Pakete)
- Neuer Server, dragonfruit.foodsharing.de
- AMD Opteron(TM) Processor 6272 (16 x 1.4-2.4 GHz, ~2011)
- 32 GB Ram (ECC)
- 4x 240 GB SSD als RAID10 (effektiv ~30000 IOPS read, ~12000 IOPS write)
- Debian 9, stretch (+ viele aktuelle Pakete)
Lust, dabei zu sein?
Hat dich dieser Beitrag angefixt, auch Teil eines ehrenamtlich arbeitenden Teams mit diversesten Aufgaben und dem Interesse, einfach mal neue Dinge ausprobieren zu können, zu werden?
Hier findest du unsere Devdocs, mit einem Teil der Aufgaben, bei denen wir noch nach Unterstützung suchen.
Melde dich gerne per Mail bei it@foodsharing.network oder im #foodsharing-dev Kanal auf dem yunity Slack! Du wirst herzlich empfangen werden :-)